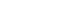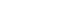Dictionary creation using CSV - William Shakespeare Thesaurus
This is intended for word-geeks who want to look more in-depth at creating a specific dictionary (thesaurus) using CSV format.
Let’s just do it by following an example.
We are going to make a better Shakespearean thesaurus than we get by just loading TXT book.
First, we will start by downloading the The Complete Works of William Shakespeare from project Gutenberg in Plain Text UTF-8 format.
Open the txt file, it could be in notepad or in CQuill (Cquill will add it to the project) and remove any text that is not part of the book - that is the beginning
“This eBook is for the use of anyone anywhere…” because we don’t want Shakespearean dictionary to know words like ebook, or ‘electronic’ and then also
from the end which is a long paragraph about project Gutenberg. “*** END OF THE PROJECT GUTENBERG EBOOK”, because again, we don’t want Will to
talk like 21st century lawyer.
Now save the file (or export from CQuill to txt (Document Export As…)
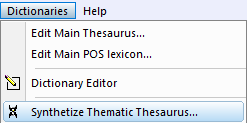
The standard, easy method is to go to Dictionaries - Synthetize Thesaurus and we will start with that. This would automatically fill the dictionary with as
many words as it could guess.
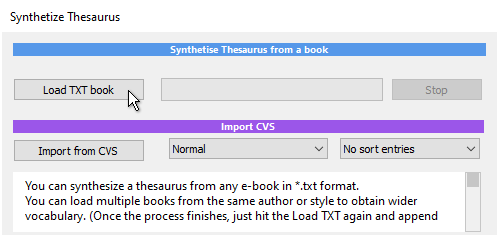
At this moment, there is not much to it, just load the *.txt book you just cleaned in previous step and wait a few minutes. The system will churn the words,
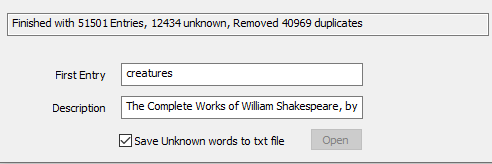
and when it is finished, look at the bottom. Check the Save Unknown words to txt file, and then hit Save and name your dictionary. For example
myShakespeare.dic. The AI word cruncher created 51 thousand entries with still yet about 12 thousand unknown words. (Your numbers may be different,
as there may be improvements in the dictionary over time)
Saving will create the dictionary *.dic file and also save a file called
MyShakespeare_unknown.csv.txt
This is a txt file formated as standard csv - a comma separated table. You can open
it in notepad, or hit the Open button on the dialog and it will open the file for you.
The “unknown” text file consist of two parts
No Synonyms part and Unknown/misspelled words following it.
The ‘no synonyms’ part are words that we know for sure to be English words. Some are
names and they would not have synonyms. Other are a various archaic forms. But none of
those are our concern right now.
The bottom part of the TXT file does list words that are completely unknown to Vocabulary
Synth, either misspelled, or in this case many would be specific to how Shakespeare wrote.
Like unwash’d or anchor’d.
The weird format you see is the CSV format. Except it is missing the head word, hence it
starts with a comma.
So line ,(),anchor’d means:
missing_head_word,(missing_POS_type),anchord’d
Note: The second item in parenthesis is POS type. JJ means Adjective.
In general, POS types for the dictionary can be:
•
(noun) or (NN) - Noun
•
(verb) or (VB) - Verb)
•
(adj) or (JJ) - Adjective
•
(adv) or (RB) - Adverb
In order to fill the missing head-word we would have to write in the document:
unwashed,(VB),unwash'd
You can certainly do it in the notepad, but CQuill has a pretty awesome spreadsheet document. So why don’t we fire it up! It will make things much easier.
Create new Wordsheet, then go to menu Document and use Import CSV.
Alternatively you can just copy and paste the lines from the notepad to the Wordsheet and it will format them as a table.
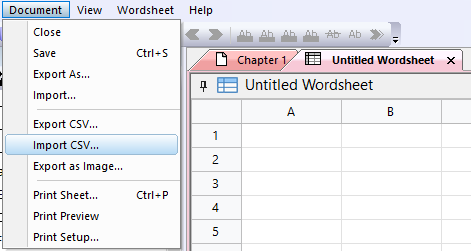
So here we have a huge table (12000 or so lines - yours may vary). I don’t think we are going to manually fill all the missing entries, but we can at least
fill some by search and replace.
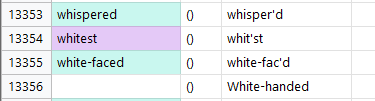
There seems to be quite a few shortened words where instead of -ed, are ‘d, like unwash’d
That’s easy to fix- but remember, we don’t want to replace words on the right side, These are the
Shakespearen words that we WANT. We are missing English head-words so we need to create them
in the first column. Let’s use the power of Wordsheets.
First select the whole column, by clicking on its header [C]
Now hit Ctrl+C to copy all the cells bellow. We need them in the first column, but for now, let’s just paste them temporarily to some free column on the right
side. Just select another empty column and hit CTR+V. Be patient, you are working with 20k lines!
So now we have a column where we can mess with the words and turn them into today’s English. With the [D] column still selected go to menu Wordsheet
and select Replace Selection.
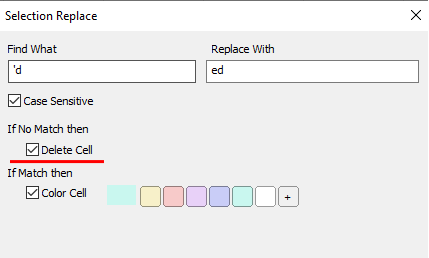
We are going to replace ‘d with ed
Note the Delete cell check box. This indicates that if there is no match (the word has no ‘d in it)
we also want to delete that cell. Now run it.
The text in column D will disappear, but wait! Scroll down to find the replaced items.
These are our new head words. Now we can copy the column D over to the column A where it belongs (again select the very top header [D], then CTR+C, ,
select header [A], CTRL+V), then delete the column [D] as we don’t need it anymore (select the header [D] and press DEL)
Let’s just explain what we had done. The first column is the head word, that is the word you are searching the dictionary for. In Shakespearean
Thesaurus, these would be English words. The second is the POS file - the 0 you see in the table is not zero, these are empty () parenthesis.
The few lines we successfully replaced would mean that if we search our thematic thesaurus for word like renewed, the thesaurus will offer us renew’d
As you go through the lines you may see that replacing ‘d was not enough. In
general Shakespeare seemed displeased with e, but there are also other short
versions like: whatsoe’er
We will go about it the same way, copy the entire column C into column D as a temporary place (you can also copy it to a new Wordsheet if this is what
you prefer!) and then replace let say ‘red with ered.
But after that, how do we merge the newly fixed column [D] with the already somehow populated column [A]? That’s easy, just paste it over as before.
If the cell doesn’t exist (and we instructed the replace command to Delete cells that do no match) it won’t be pasted over. A deleted cell does not have
an empty string - it has nothing, it doesn’t exist, so it cannot be pasted over anything. Just try it, it works!
The same way we can replace ‘ry, ‘st, ‘red, ‘ring, ‘er one at the time, then merge the column with the A column. Now if you look at the A column, there
are still some words that may have ‘ in them. If you are going to replace those directly in the column A, make sure you uncheck the Delete cell, so you
won’t delete the words you already fixed before! You can manually change things here and there, delete entries that are completely useless and then
just save the CSV file by going to Document - Export CSV.
You may have noticed that we didn’t care about the missing POS type and that’s because if it is not specified (or a bogus entry, like empty parenthesis
we have right now), the import process will try to determine the type itself.
You could also experiment trying to replace eth with es. For example accuseth > accuses, but you should look at the results, because it would also
replace words like Elizabeth and mess up with other words.
Let’s go back to our Synthetize Thematic Thesaurus. Here we will use the Import CSV button, but before that, let’s talk about the options:
Unlike the TXT import, the CSV has a few peculiar options that don’t say
much. To be honest, they were mostly added when we were building some
of our thesauri (plural of thesaurus apparently).
If nothing else, it could be a note for future ourselves.
CSV Import options:
Normal
It creates the headword, and fill the entry with the other words on the line in CSV file - so this option creates one entry per line in the dictionary. No
trickery.
The CVS line: happy,(JJ), jolly, merry
Creates:
•
happy,(JJ), jolly, merry
Symmetrical self-reference
The idea is that if the word happy has synonym jolly and merry, then both merry and jolly should have synonym happy. This works in many cases,
unless the entry is a bit free spirited. For example the 1911 Roget’s thesaurus that we used as part of our General Thesaurus has only some 1400
entries, but each entry has ten, twenty or sometimes more words in them. Symmetrical reference would magically create 40000 entries out of it. Sadly,
many would be pretty big stretch, mostly because the 1911 thesaurus takes synonyms more as “somehow” similar words, but not entirely.
Hence, this option should be used if you can vouch for the word’s in entry (or for example if there is only one entry like in our case. Both whatsoe’er and
whatsoever are obviously interchangeable.
The CVS line: happy,(JJ), jolly, merry
Creates:
•
happy,(JJ), jolly, merry
•
jolly,(JJ),happy
•
merry,(JJ),happy
Cyclical Reference
Now, you may be saying: shouldn’t jolly also have merry as synonym? Yes and no. In this case it would work fine and the entry : jolly,(JJ), happy, merry
would work. But there are many cases where this wouldn’t be true. The words in the entry are synonym to the head-word, sometimes even symmetrical,
but not all of them will be synonyms to each other. We are not going to look through 40 thousand entries, are we?
This option would creates gigantic cross-referenced thesaurus with hundred thousand of words in it, but it would be a pretty sorry thesaurus, giving you
synonyms that would require a suspension of belief.
Now this option still exist, because there is a valid reason, for example if you are building a Rhyming dictionary. If the headword rhymes with the entry
words, so should all the entries in some way rhyme with each other.
Normally doing something like this would create a huge file (we are talking about Gigabytes), and that would be of no use, so there is another trick -
Pointer Reference. It basically creates only one entry per line, but then it goes word by word through the entries and creates a fake - pointer only -
headword that points to the original entry.
The CVS line: happy,(JJ), jolly, merry
Creates:
•
happy,(JJ), jolly, merry
•
jolly,(JJ), >[see happy]
•
merry,(JJ),>[see happy]
The file will be very small, but hugely criss-cross-referenced. The downside is that editing would be nearly impossible as most of the entries just point
somewhere else. There isn’t much more use besides the Rhyming dictionary, to be honest.
Reverse dictionary
This is like the symmetrical self reference, except it never creates the original entry:
The CVS line: happy,(JJ), jolly, merry
Creates:
•
jolly,(JJ),happy
•
merry,(JJ),happy
Why we would ever want something like that? Yes we do, and a lot of times! Imagine you are building a thematic thesaurus, and let’s take Shakespeare
as an example:
•
haggard,(JJ), wild, unmanageable, untrainable
Now you see, building thematic thesaurus with CSV like that actually makes zero sense. If we search for haggard, we will get synonyms wild,
unmanageable, untrainable, but that is not what we want at all. That would be a translation from Shakespearean to English. We want to type ‘wild’ and
see Shakespearean ‘haggard’. So Reverse Dictionary.
In fact we actually don’t want word unmanageable or untrainable as the synonyms in the dictionary at all, because Shakespeare never used these words
(He did use ‘wild’ though with many other meanings).
Hence the first entry where wild, unmanageable and untrainable is on the right side, like written above will and should NEVER be created in a thematic
dictionary, and if you need to have wild there, then you need to define it like so: wild,(JJ),wanton, flighty, frivolous and use Reverse Dictionary option.
AI Expand Head Word
Here is a bit of trickery, let’s go back to our original CSV file and pick one entry
•
imprisoned,(JJ),imprison'd
The thing is, there are many other words that word imprison’d is synonym to (like jailed) which we don’t have in the CSV. But using this option will create
them anyway!
It will create entries like:
•
imprisoned,(JJ),imprison'd
•
jailed,(JJ),imprison’d
•
incarcerated,(JJ),imprison’d
Granted, we are using a bit of leap of faith here, but in general it works, and creates much more robust thesaurus for free. Let’s just try Normal at first
with our CSV file:
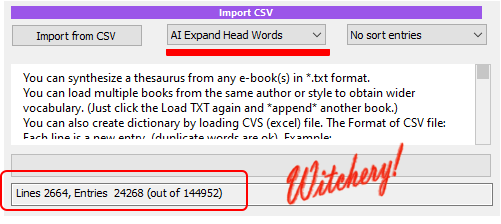
Click the Import from CSV and select the file we created in previous step.
So we got good 2719 entries (head-words) from our big CSV. As you remember,
most of the lines were empty without the head-word so they don’t get
imported.
This time it took a bit longer but we somehow created 24 thousand entries. What!?
In fact the process created 145 thousand entries, but then many entries were
merged and cleaned.
We do use leap of faith here, hoping that the synonyms to the head-words are
reasonable. In most cases they are, but there could be questionable items. You
can’t have free lunch though.
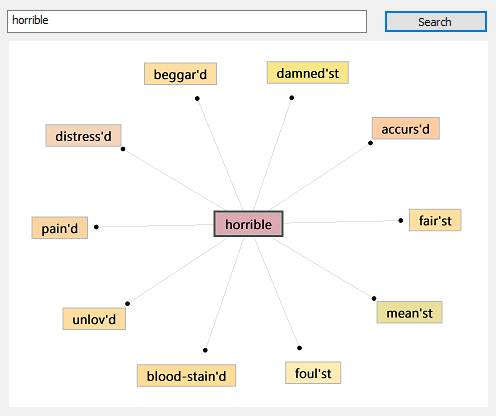
Let’s try AI Expand Head Word option
Ok, let’s test test it. We can do it still in the same window.
Just type word “horrible” into the box and hit search.
As you can see, we have a pretty interesting hits.
If you tried the same word in the previous (Normal) option, you will get zero hits.
Of course we never had word ‘horrible’ in CSV file. So we’ve got a lot for a very
little using some trickery.
You may try some other words - mostly verbs as that is what we have in the CSV
file. Yes, there will be misses here and there, but we’ve got an entire thesaurus
build from almost nothing.
Wait, that’s actually not our thesaurus! Didn’t we use the Complete Works of
William Shakespeare to create the thesaurus? Because we are playing right now
only with the unrecognized words!
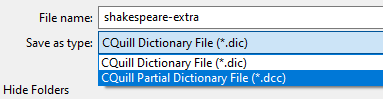

Hit the save button and select CQuill Partial Dictionary File *.dcc as the type.
The reason for *.dcc instead of *.dic is that dcc files won’t be seen by CQuill as viable
dictionaries to show in the Thesaurus selection. And that’s what we want, this is still a
partial dictionary.
Otherwise, they are the same file format.
Let’s sum up where we are:
We have myShakespeare.dic file created from the Complete works of William Shakespeare. These are words that the system recognized. Then we
took the *unknown file and exctracted a few thousand words that we could fix quickly without going through them manually and we created
shakespeare-extra.dcc
Now we need to put them together. At this moment I would suggest to make copy of the myShakespeare.dic as it may come in handy.
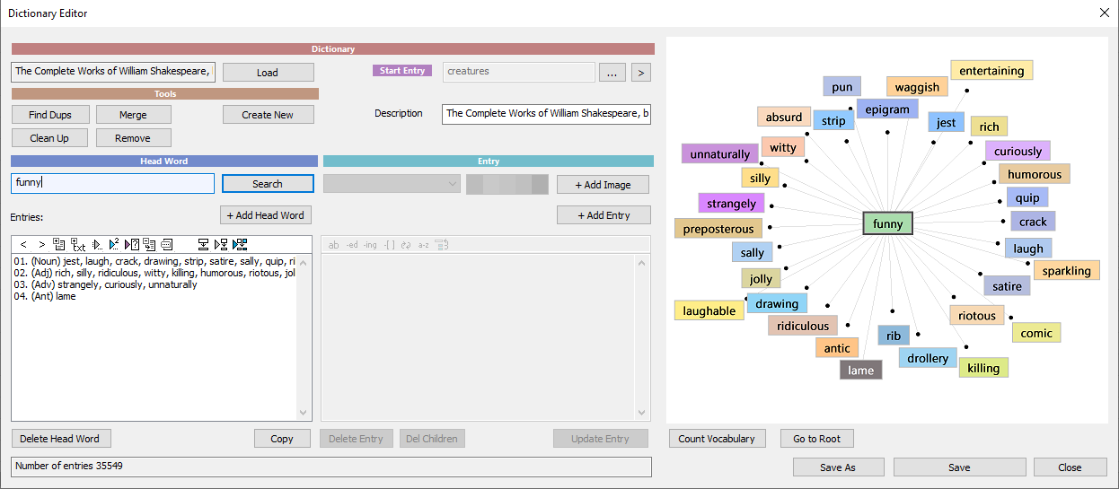
For the next part we use our Dictionary Editor
Fine, let’s save it
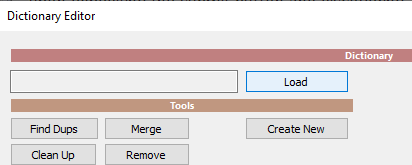
Once there, hit the Load button and
load the myShakespeare.dic

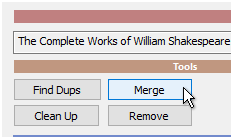
Now we can hit Merge button and then locate the dcc file we created from the CSV words to Merge the CSV created dictionary with this one.
Now our dictionary grew with additional entries and much more words in those entries.
The same way we can add other words, filling the missing entries in the *unknown file, or creating a whole new CSV file
from words we can find online.
The result dictionary will be created with
William Shakespeare words, but only the
ones we recognize today.
The process will omit any unknown words
(and in the case of Shakespeare, that
would be a good 40%!)

Tip: To scroll faster through 20k lines, hold down Shift while turning the mouse wheel.
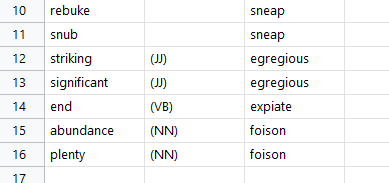
This dictionary has already a lot’s of words. Let’s try a few:

Now, let’s try again. And here we go - the entry ‘funny’ got a few new words like
crook’d.
Despite the fact that we didn’t fill much of the 20K
unknown words, the Shakespearean thesaurus is
already shaping up. But of course we can fix it even
further by trying to locate the missing keywords from
web.
To be continued….
We will try to refine the dictionary using Index, Web Crawler in the next chapter
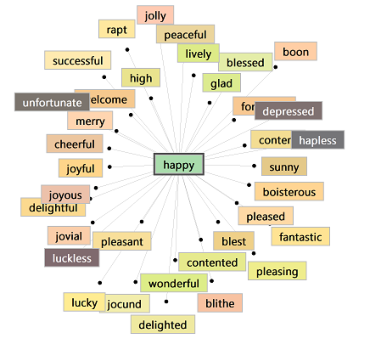
We could already test the dictionary and type a few words in the search entry to see the suggestions.
These would be all words that Shakespeare would use, but they are no surprises.
This is because the Vocabulary Synth doesn’t fully understand the way Shakespeare wrote and as you
can see, a good chunk (12k) words were thrown in the Unknown file. These would be the typically
peculiar words, that we could, at least partially, sneak in back to the thesaurus.